The gradual deprecation of third-party cookies has not simply removed a tracking technology. It has fundamentally challenged the way brands build, maintain, and activate the digital identity of their users. In a context shaped by increasingly restrictive browsers, stricter privacy regulations, and rising consumer expectations, identity resolution can no longer be treated as an ancillary function of the martech stack, but as a long-term strategic asset.
In this cookieless scenario, identity resolution platforms become a key element to ensure cross-channel continuity, data consistency, and activation capabilities, without relying on opaque identifiers or external ecosystems. The focus shifts toward first-party approaches, designed to enhance proprietary data, enable ID bridging processes, and structure a solid digital identity graph within the modern data stack.
This guide does not aim to redefine what identity resolution is, but to provide a practical and architectural framework on how to design it, evaluate it, and make it operational in a scalable, privacy-first, compliant way that is truly ready for activation across marketing, media, and analytics.
Why Cookieless Identity Resolution Requires a New Architectural Approach
In the cookie-based paradigm, digital identity was often inferred after the fact rather than designed in a structured way. Third-party cookies long acted as a technical shortcut: a probabilistic mechanism that was opaque and increasingly unreliable, especially in terms of control, data quality, and compliance.
In the transition to a cookieless scenario, identity resolution requires a radically different approach. It can no longer rely on fragile correlations, but must be designed according to clear principles:
- Deterministic, where possible, to ensure consistency and repeatability over time.
- First-party by design, grounded in proprietary and legitimately collected identifiers.
- Persistent across the entire user lifecycle, spanning different channels and devices.
- Independent from media platforms, to avoid technological and informational lock-in.
- Directly governed by the brand, in terms of logic, priorities, and usage policies.
This paradigm shift moves identity resolution from a tactical adtech function to a foundational layer on which analysis, prediction, and activation are built.
From this perspective, a modern cookieless identity solution is no longer a simple plug-in or tracking layer, but a central architectural component positioned between data collection, analytics, AI modeling, and omnichannel activation.
First-Party Identity Resolution: From Data Ownership to Control
At the core of any truly sustainable cookieless strategy lies first-party identity resolution. In the absence of third-party cookies, the only way to ensure continuity and control over identity is to build it from identifiers that the brand owns, governs, and can legitimately use.
Unlike third-party-based approaches, first-party identity resolution relies exclusively on proprietary identifiers, including:
- Hashed emails (HEM)
- CRM IDs or customer IDs
- User IDs associated with authenticated sessions
- Loyalty, membership, or subscription identifiers
Identity is therefore represented by a plurality of identifiers that coexist because they are used as data exchange formats across different platforms. Alternative IDs, specific PIIs, or customer identifiers are often adopted to meet integration, activation, or compliance requirements of individual systems. The result is an ecosystem in which the same individual is represented by multiple legitimate IDs that are distributed and misaligned.
The critical issue is not the nature of the identifier itself, but its coherent and governed adoption as a linking key across heterogeneous datasets. Without a structured logic to relate these IDs, even the best identifiers remain isolated, difficult to query, and poorly activatable in a consistent way.
ID Bridging: Connecting Fragmented Identities Over Time
Even in a fully first-party context, digital identity is never static nor immediately complete. Users may start browsing anonymously, authenticate at a later stage, switch devices, or alternate between digital and physical interactions. It is within this fragmented dynamic that ID bridging becomes a structural element of identity resolution.
ID bridging refers to the controlled and deterministic process through which multiple identifiers attributable to the same individual are connected over time. In practical terms, this means associating an anonymous session ID with an authenticated user ID at login, reconciling a CRM ID with a hashed email (HEM) used in other systems, or linking online identifiers with in-store transaction IDs, thereby reconstructing a continuous customer journey across digital and physical touchpoints.
A mature approach to ID bridging does not simply overwrite identities or impose a static, single key. Instead, it preserves the relationships between identifiers, maintaining their history, temporal sequence, and context of origin. Identity is thus treated as a set of evolving connections rather than a rigid entity defined once and for all.
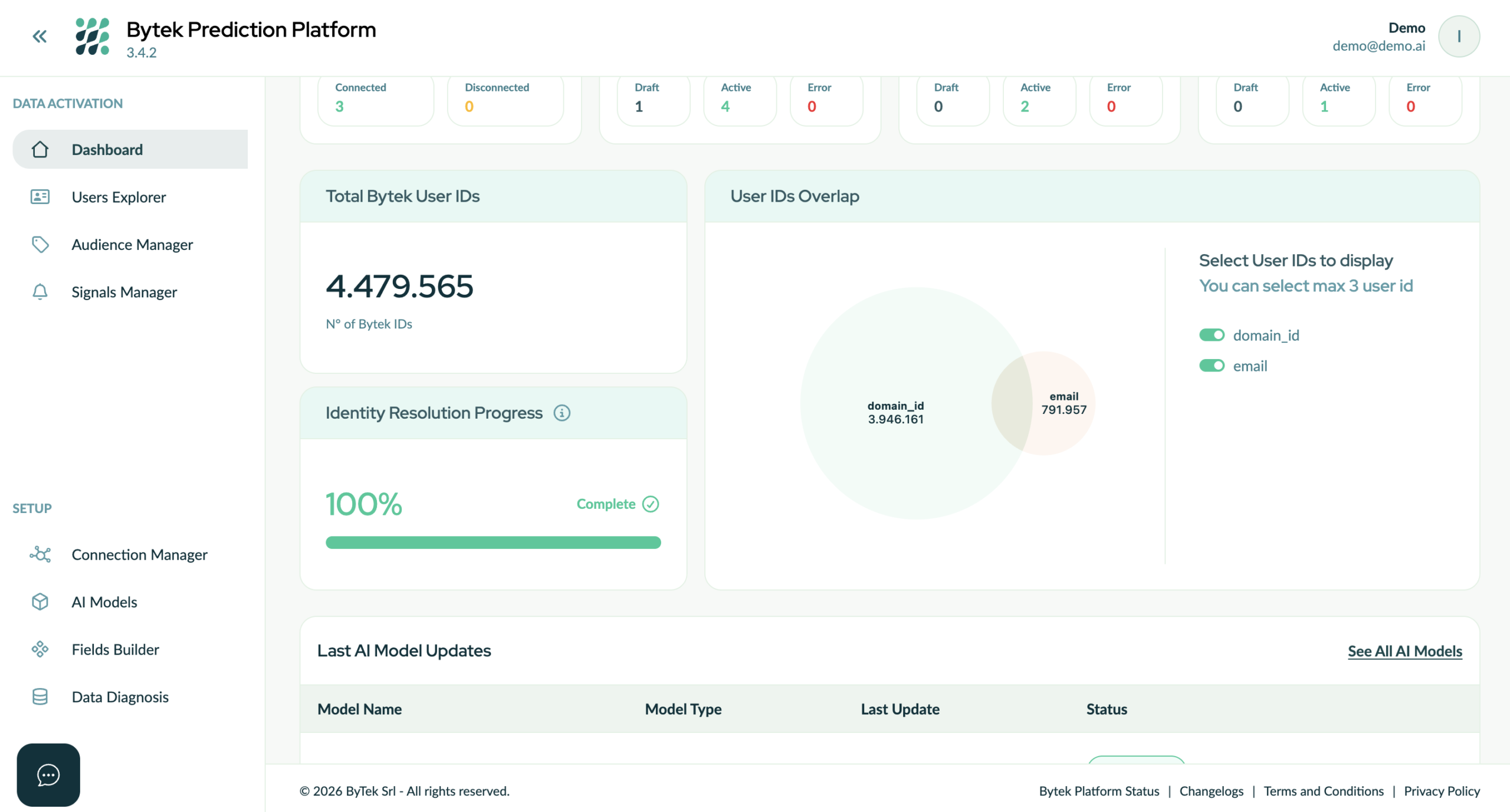
IMG – Bytek Prediction Platform can link the different identifiers used in the data warehouse and originating from various enterprise systems, generating a unique Bytek ID that connects the different sub-IDs.
This model enables retrospective identity stitching, supports accurate attribution even across long conversion cycles, and allows the creation of coherent, activatable audiences even when signals are partial or intermittent. In this sense, ID bridging is what allows identity resolution to scale realistically, adhering to the complexity of real customer journeys without sacrificing data quality, governance, or analytical reliability.
The Digital Identity Graph as a Strategic Asset
When identity resolution is implemented correctly, the outcome is not simply a unified profile, but the construction of a digital identity graph. This model represents identity as a dynamic network, where users are central nodes connected to identifiers, devices, and touchpoints through relationships that evolve over time.
Unlike traditional customer tables, which are static and rigid, an identity graph is dynamic and extensible. It can incorporate new signals, new identifiers, and new interactions without losing historical coherence. Because of this structure, it is particularly well suited for advanced analytics and AI-driven use cases, where identity quality and continuity are fundamental prerequisites.
Within this framework, marketing and data teams can:
- Query audiences across different channels and time windows.
- Progressively enrich profiles with behavioral and transactional features.
- Feed predictive models with coherent and persistent identity signals.
- Activate insights and segmentations without duplication, fragmentation, or system conflicts.
In this sense, the digital identity graph becomes the true backbone of decision intelligence: not a simple matching mechanism, but the infrastructure that enables consistent understanding, prediction, and activation of customer behavior.
The Role of Bytek Tag by Adenty in Cookieless Identity Resolution
Bytek Tag by Adenty enables the collection of navigation and digital interaction signals across multiple domains and sessions, generating a persistent probabilistic identifier. This identifier makes it possible to recognize the same user over time, reducing the fragmentation typical of cookieless environments and maintaining continuity even when deterministic identifiers are not immediately available.
When users voluntarily provide identifying data, such as an email address, Bytek Tag manages its collection in hashed form, in line with privacy-by-design principles.
Personally Identifiable Information (PII), collected exclusively on a voluntary basis and processed in hashed form, is used to stabilize and consolidate identity over time. This allows interactions and signals that would otherwise remain fragmented in the absence of login to be associated more reliably.
In this context, Bytek Tag helps ensure identity continuity across sessions and domains, supporting event reconciliation and the evolution of profiles from probabilistic identifications to more stable ones. This consistency makes data usable in a coherent way throughout the entire lifecycle within the modern data stack.
Identity Resolution Platforms and the Modern Data Stack
Historically, identity resolution has been handled as an ancillary capability within advertising, CRM, or marketing automation tools. In these legacy models, identifier linking was often limited to individual channels, based on incomplete datasets and heavily dependent on third-party cookies or external identifiers. The result was a fragmented view of the user, difficult to maintain consistently over time and poorly suited to structured personalization, measurement, and governance.
Identity resolution platforms emerged to overcome these limitations, introducing a dedicated solution for managing identity across the entire customer journey. Their role is to connect signals from online and offline sources, recognize both known and anonymous users, and make identity consistently usable within targeting, measurement, and personalization processes.
Enterprise identity resolution platforms today share a core set of capabilities. They support data onboarding and matching across heterogeneous sources, build an identity graph representing relationships between individuals, devices, and touchpoints, enable brands to retain full ownership of first-party data, and leverage persistent identifiers at an individual or household level. In this context, identity is not treated as a static state, but as an evolving structure, where historical data can be retroactively reconciled as new identifiers or authentication signals emerge. These capabilities are complemented by compliance features, consent management, and integration with third-party systems via APIs.
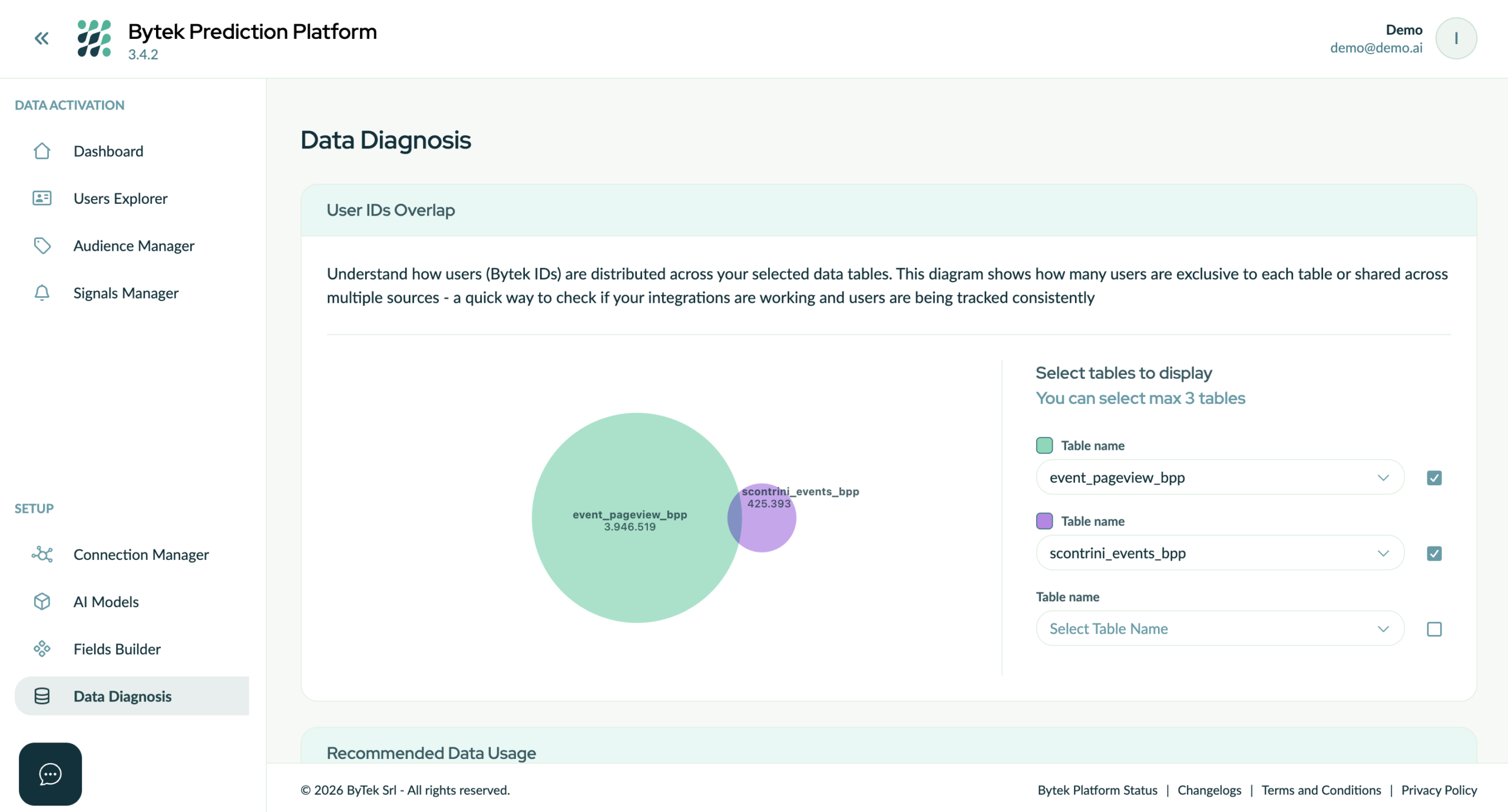
IMG – After launching identity resolution, Bytek Prediction Platform applies it directly to the data warehouse tables, enabling the identification of overlap between tables in terms of recognized users.
Beyond this common core, many platforms offer advanced functionalities that expand their scope of use, including match confidence scoring, integration with data clean rooms, private or cooperative identity graphs, and prebuilt connections with the martech and adtech ecosystem. In this way, identity resolution evolves from a simple deduplication process into a central component of the marketing infrastructure.
From a benefits perspective, adopting an identity resolution platform enables deeper customer insights, improves personalization accuracy, and delivers more consistent experiences across channels. At the same time, the use of persistent identifiers supports more reliable cross-channel measurement, stronger attribution models, and more rigorous management of privacy, preferences, and compliance.
Privacy, Compliance, and Trust by Design
The ability to recognize users today must coexist with a stricter regulatory landscape and growing consumer attention to how personal data is used.
In this context, a truly robust identity resolution platform must be designed from the outset to avoid processing personal data in clear text, rely on encrypted and anonymized identifiers, consistently respect consent signals across systems, and ensure auditability and data governance throughout the entire data lifecycle.
When identity is resolved within first-party boundaries and managed directly at the data layer level, compliance with regulations such as GDPR and CCPA is no longer an after-the-fact constraint, but a structural characteristic of the architecture. This is precisely the approach that allows personalization and activation to scale without compromising user trust, making privacy and performance complementary dimensions rather than opposing ones.
How to Evaluate a Cookieless Identity Solution
When evaluating an identity resolution platform in a cookieless scenario, marketing and data leaders should ask a set of key questions to distinguish truly structural solutions from partial or purely tactical approaches:
- Is the solution first-party by design, or does it still rely on external identifiers and third-party ecosystems?
- Does it support deterministic ID bridging processes and the retroactive reconciliation of identities over time?
- How is identity managed architecturally: within a proprietary, closed system, or in an integrable and queryable way across the existing data ecosystem?
- Are identity resolution outputs accessible and reusable across analysis, modeling, and activation layers, or are they confined within the platform itself?
From this perspective, a cookieless identity solution should not be evaluated solely on match rate, but on how effectively identity can be used as a shared asset to support insight, prediction, and activation in a coherent and sustainable way over time.
The Bytek Approach to Cookieless Identity Resolution
Within this framework, the Bytek Prediction Platform interprets identity resolution as a structural function supporting analysis and prediction, rather than as an isolated output or a simple profile unification layer. Identity is resolved by linking identifiers, events, and attributes from heterogeneous sources, with the goal of ensuring continuity and coherence across the entire user lifecycle.
The Bytek Prediction Platform operates directly within the data warehouse environment, avoiding data duplication and keeping relationships between identifiers explicit and queryable. In this way, identity resolution becomes the operational foundation on which predictive models such as propensity, churn, or Customer Lifetime Value are built, allowing them to work on non-fragmented, historically consistent profiles.
This approach enables brands to fully leverage first-party data while retaining complete control, support advanced ID bridging processes, and power marketing and media activations based on predictive insights, all in line with privacy-by-design principles.




