La graduale dismissione dei cookie di terze parti non ha semplicemente rimosso una tecnologia di tracciamento. Ha messo fondamentalmente in discussione il modo in cui i brand costruiscono, mantengono e attivano l’identità digitale dei propri utenti. In un contesto plasmato da browser sempre più restrittivi, normative sulla privacy più severe e crescenti aspettative dei consumatori, la risoluzione dell’identità non può più essere trattata come una funzione accessoria dello stack martech, ma come un asset strategico a lungo termine.
In questo scenario cookieless, le piattaforme di identity resolution diventano un elemento chiave per garantire continuità cross-canale, coerenza dei dati e capacità di attivazione, senza fare affidamento su identificatori opachi o ecosistemi esterni. L’attenzione si sposta verso approcci first-party, progettati per valorizzare i dati proprietari, abilitare processi di ID bridging e strutturare un solido digital identity graph all’interno del moderno stack di dati.
Questa guida non mira a ridefinire cos’è l’identity resolution, ma a fornire un quadro pratico e architettoniale su come progettarla, valutarla e renderla operativa in modo scalabile, privacy-first e conforme, che sia realmente pronto per l’attivazione tra marketing, media e analytics.
Perché la Cookieless Identity Resolution richiede un nuovo approccio architettonico
Nel paradigma basato sui cookie, l’identità digitale veniva spesso dedotta a posteriori piuttosto che progettata in modo strutturato. I cookie di terze parti hanno agito a lungo come una scorciatoia tecnica: un meccanismo probabilistico che era opaco e sempre più inaffidabile, specialmente in termini di controllo, qualità dei dati e conformità.
Nella transizione verso uno scenario cookieless, l’identity resolution richiede un approccio radicalmente diverso. Non può più basarsi su correlazioni fragili, ma deve essere progettata secondo principi chiari:
- Deterministica, dove possibile, per garantire coerenza e ripetibilità nel tempo.
- First-party by design, basata su identificatori proprietari e raccolti legittimamente.
- Persistente lungo l’intero ciclo di vita dell’utente, spaziando tra diversi canali e dispositivi.
- Indipendente dalle piattaforme media, per evitare il lock-in tecnologico e informativo.
- Direttamente governata dal brand, in termini di logiche, priorità e policy di utilizzo.
Questo cambio di paradigma sposta l’identity resolution da una funzione adtech tattica a un livello fondamentale su cui si costruiscono analisi, previsioni e attivazioni.
In quest’ottica, una moderna soluzione di identità cookieless non è più un semplice plug-in o un livello di tracciamento, ma una componente architettonica centrale posizionata tra la raccolta dati, l’analisi, la modellazione AI e l’attivazione omnicanale.
First-Party Identity Resolution: dalla proprietà dei dati al controllo
Al centro di ogni strategia cookieless realmente sostenibile c’è la first-party identity resolution. In assenza di cookie di terze parti, l’unico modo per garantire continuità e controllo sull’identità è costruirla a partire da identificatori che il brand possiede, governa e può utilizzare legittimamente.
A differenza degli approcci basati su terze parti, la risoluzione dell’identità di prima parte si affida esclusivamente a identificatori proprietari, tra cui:
- Email sottoposte a hashing (HEM)
- ID CRM o ID cliente
- User ID associati a sessioni autenticate
- Identificatori di fedeltà, membership o abbonamento
L’identità è quindi rappresentata da una pluralità di identificatori che coesistono perché utilizzati come formati di scambio dati tra diverse piattaforme. ID alternativi, PII specifiche o identificatori cliente vengono spesso adottati per soddisfare i requisiti di integrazione, attivazione o conformità dei singoli sistemi. Il risultato è un ecosistema in cui lo stesso individuo è rappresentato da molteplici ID legittimi, distribuiti e disallineati.
Il problema critico non è la natura dell’identificatore in sé, ma la sua adozione coerente e governata come chiave di collegamento tra set di dati eterogenei. Senza una logica strutturata per correlare questi ID, anche i migliori identificatori rimangono isolati, difficili da interrogare e scarsamente attivabili in modo coerente.
ID Bridging: connettere identità frammentate nel tempo
Anche in un contesto completamente first-party, l’identità digitale non è mai statica né immediatamente completa. Gli utenti possono iniziare a navigare in modo anonimo, autenticarsi in una fase successiva, cambiare dispositivo o alternare interazioni digitali e fisiche. È all’interno di questa dinamica frammentata che l’ID bridging diventa un elemento strutturale della risoluzione dell’identità.
L’ID bridging si riferisce al processo controllato e deterministico attraverso il quale più identificatori attribuibili allo stesso individuo vengono collegati nel tempo. In termini pratici, ciò significa associare un ID sessione anonimo con un ID utente autenticato al momento del login, riconciliare un ID CRM con una email sottoposta a hashing (HEM) utilizzata in altri sistemi, o collegare identificatori online con ID transazione in-store, ricostruendo così un customer journey continuo tra touchpoint digitali e fisici.
Un approccio maturo all’ID bridging non si limita a sovrascrivere le identità o a imporre una chiave statica e singola. Al contrario, preserva le relazioni tra gli identificatori, mantenendone la storia, la sequenza temporale e il contesto di origine. L’identità viene così trattata come un insieme di connessioni in evoluzione piuttosto che come un’entità rigida definita una volta per tutte.
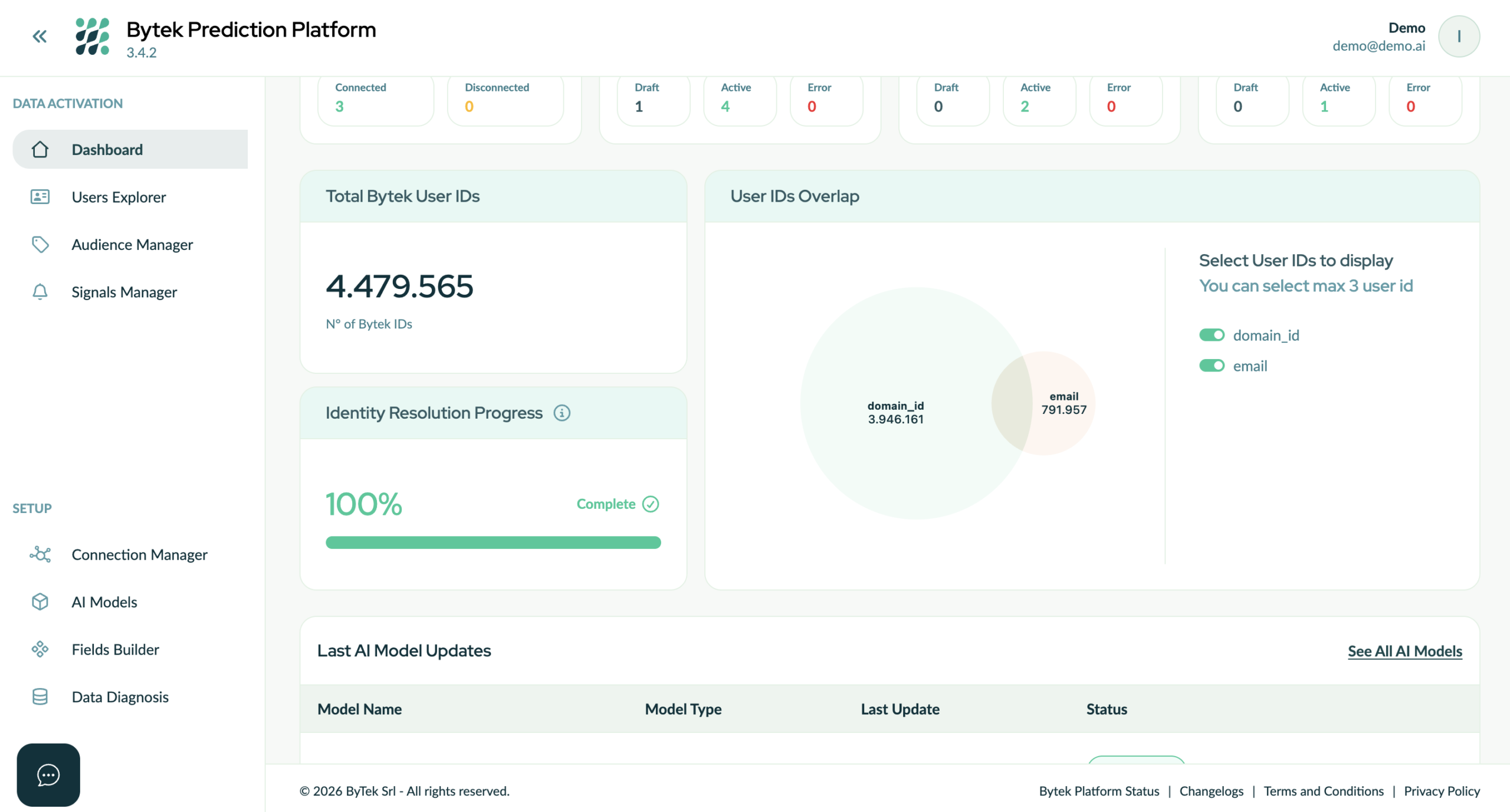
IMG – Bytek Prediction Platform può collegare i diversi identificatori utilizzati nel data warehouse e provenienti da vari sistemi aziendali, generando un Bytek ID univoco che connette i diversi sub-ID.
Questo modello abilita lo stitching retrospettivo dell’identità, supporta un’attribuzione accurata anche su cicli di conversione lunghi e consente la creazione di audience coerenti e attivabili anche quando i segnali sono parziali o intermittenti. In questo senso, l’ID bridging è ciò che permette alla risoluzione dell’identità di scalare realisticamente, aderendo alla complessità dei reali percorsi dei clienti senza sacrificare la qualità dei dati, la governance o l’affidabilità analitica.
Il Digital Identity Graph come asset strategico
Quando l’identity resolution è implementata correttamente, il risultato non è semplicemente un profilo unificato, ma la costruzione di un digital identity graph. Questo modello rappresenta l’identità come una rete dinamica, in cui gli utenti sono nodi centrali collegati a identificatori, dispositivi e touchpoint attraverso relazioni che si evolvono nel tempo.
A differenza delle tradizionali tabelle clienti, che sono statiche e rigide, un identity graph è dinamico ed estensibile. Può incorporare nuovi segnali, nuovi identificatori e nuove interazioni senza perdere la coerenza storica. Grazie a questa struttura, è particolarmente adatto per analisi avanzate e casi d’uso AI-driven, dove la qualità e la continuità dell’identità sono prerequisiti fondamentali.
All’interno di questo framework, i team di marketing e dati possono:
- Interrogare le audience su diversi canali e finestre temporali.
- Arricchire progressivamente i profili con caratteristiche comportamentali e transazionali.
- Alimentare i modelli predittivi con segnali di identità coerenti e persistenti.
- Attivare insight e segmentazioni senza duplicazioni, frammentazioni o conflitti di sistema.
In questo senso, il digital identity graph diventa la vera spina dorsale della decision intelligence: non un semplice meccanismo di matching, ma l’infrastruttura che abilita la comprensione, la previsione e l’attivazione coerente del comportamento dei clienti.
Il ruolo di Bytek Tag by Adenty nella Cookieless Identity Resolution
Bytek Tag by Adenty consente la raccolta di segnali di navigazione e interazione digitale su più domini e sessioni, generando un identificatore probabilistico persistente. Questo identificatore permette di riconoscere lo stesso utente nel tempo, riducendo la frammentazione tipica degli ambienti cookieless e mantenendo la continuità anche quando gli identificatori deterministici non sono immediatamente disponibili.
Quando gli utenti forniscono volontariamente dati identificativi, come un indirizzo email, Bytek Tag ne gestisce la raccolta in forma sottoposta a hashing, in linea con i principi di privacy-by-design.
Le informazioni di identificazione personale (PII), raccolte esclusivamente su base volontaria e trattate in forma di hash, vengono utilizzate per stabilizzare e consolidare l’identità nel tempo. Ciò consente di associare in modo più affidabile interazioni e segnali che altrimenti rimarrebbero frammentati in assenza di login.
In questo contesto, Bytek Tag aiuta a garantire la continuità dell’identità tra sessioni e domini, supportando la riconciliazione degli eventi e l’evoluzione dei profili da identificazioni probabilistiche a identificazioni più stabili. Questa coerenza rende i dati utilizzabili in modo armonioso durante l’intero ciclo di vita all’interno del moderno stack di dati.
Piattaforme di Identity Resolution e il Modern Data Stack
Storicamente, la risoluzione dell’identità è stata gestita come una funzionalità accessoria all’interno di strumenti di advertising, CRM o marketing automation. In questi modelli legacy, il collegamento degli identificatori era spesso limitato ai singoli canali, basato su set di dati incompleti e fortemente dipendente dai cookie di terze parti o da identificatori esterni. Il risultato era una visione frammentata dell’utente, difficile da mantenere coerente nel tempo e poco adatta a personalizzazione, misurazione e governance strutturate.
Le piattaforme di identity resolution sono nate per superare questi limiti, introducendo una soluzione dedicata per la gestione dell’identità lungo l’intero customer journey. Il loro ruolo è connettere i segnali provenienti da fonti online e offline, riconoscere sia gli utenti noti che quelli anonimi e rendere l’identità costantemente utilizzabile all’interno dei processi di targeting, misurazione e personalizzazione.
Le piattaforme di identity resolution aziendali oggi condividono un set di funzionalità principali. Supportano l’onboarding e il matching dei dati tra fonti eterogenee, costruiscono un identity graph che rappresenta le relazioni tra individui, dispositivi e touchpoint, consentono ai brand di mantenere la piena proprietà dei dati di prima parte e sfruttano identificatori persistenti a livello individuale o familiare. In questo contesto, l’identità non è trattata come uno stato statico, ma come una struttura in evoluzione, dove i dati storici possono essere riconciliati retroattivamente man mano che emergono nuovi identificatori o segnali di autenticazione. Queste capacità sono completate da funzioni di conformità, gestione del consenso e integrazione con sistemi di terze parti tramite API.
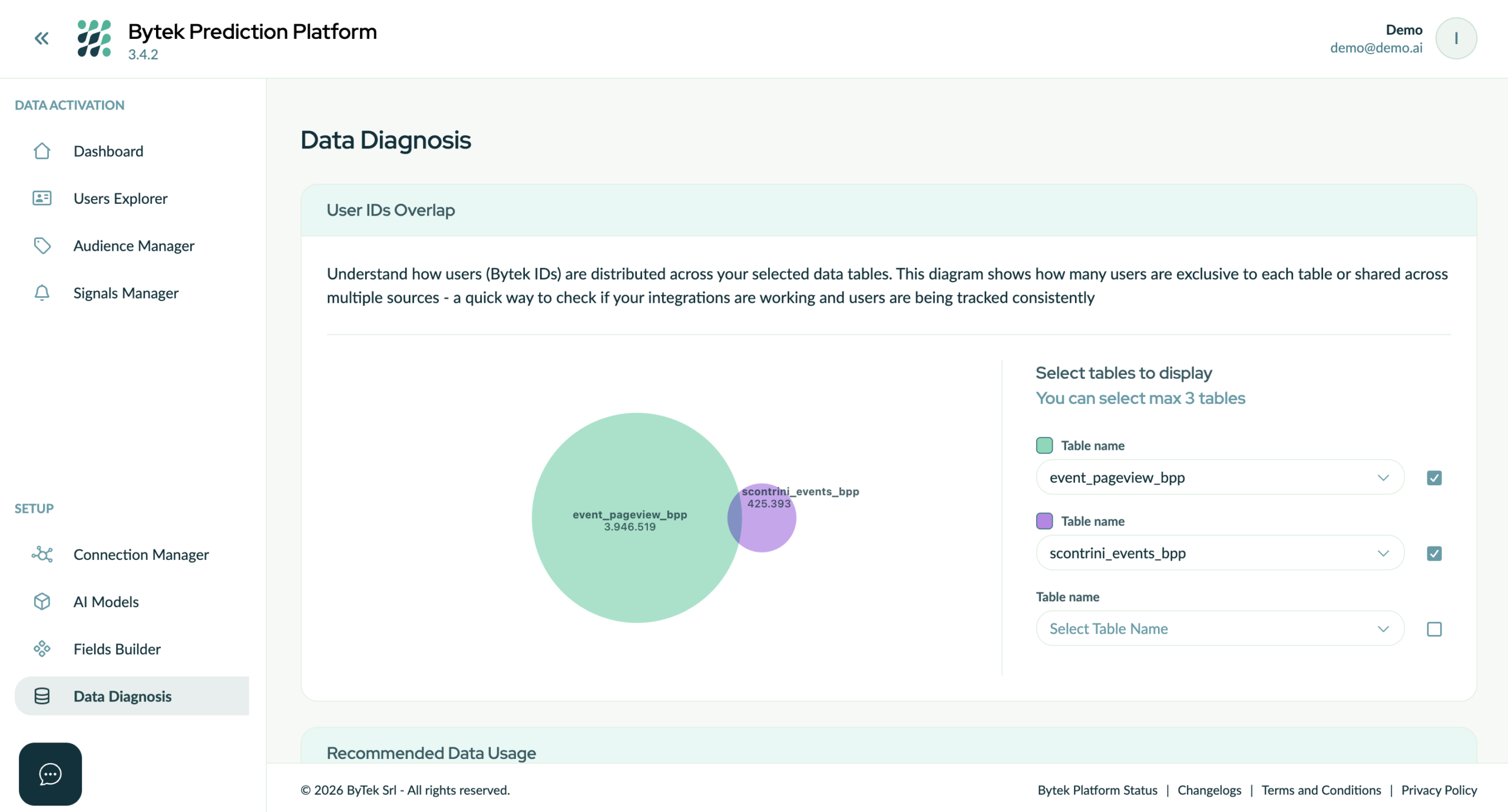
IMG – Dopo il lancio dell’identity resolution, Bytek Prediction Platform la applica direttamente alle tabelle del data warehouse, consentendo l’identificazione della sovrapposizione tra le tabelle in termini di utenti riconosciuti.
Oltre a questo nucleo comune, molte piattaforme offrono funzionalità avanzate che ne ampliano l’ambito di utilizzo, tra cui il punteggio di confidenza del match, l’integrazione con data clean room, identity graph privati o cooperativi e connessioni predefinite con l’ecosistema martech e adtech. In questo modo, l’identity resolution si evolve da un semplice processo di deduplicazione a una componente centrale dell’infrastruttura di marketing.
Dal punto di vista dei benefici, l’adozione di una piattaforma di identity resolution consente una comprensione più profonda dei clienti, migliora l’accuratezza della personalizzazione e offre esperienze più coerenti su tutti i canali. Allo stesso tempo, l’uso di identificatori persistenti supporta una misurazione cross-canale più affidabile, modelli di attribuzione più solidi e una gestione più rigorosa della privacy, delle preferenze e della conformità.
Privacy, Conformità e Trust by Design
La capacità di riconoscere gli utenti oggi deve coesistere con un panorama normativo più severo e una crescente attenzione dei consumatori al modo in cui vengono utilizzati i dati personali.
In questo contesto, una piattaforma di identity resolution veramente robusta deve essere progettata fin dall’inizio per evitare il trattamento dei dati personali in chiaro, basarsi su identificatori crittografati e anonimizzati, rispettare costantemente i segnali di consenso tra i sistemi e garantire auditabilità e governance dei dati lungo l’intero ciclo di vita del dato.
Quando l’identità viene risolta entro i confini della prima parte e gestita direttamente a livello di data layer, la conformità a normative come GDPR e CCPA non è più un vincolo a posteriori, ma una caratteristica strutturale dell’architettura. Questo è proprio l’approccio che permette alla personalizzazione e all’attivazione di scalare senza compromettere la fiducia degli utenti, rendendo la privacy e le performance dimensioni complementari piuttosto che opposte.
Come valutare una soluzione di identità cookieless
Nel valutare una piattaforma di identity resolution in uno scenario cookieless, i leader del marketing e dei dati dovrebbero porsi una serie di domande chiave per distinguere le soluzioni veramente strutturali dagli approcci parziali o puramente tattici:
- La soluzione è first-party by design, o si affida ancora a identificatori esterni ed ecosistemi di terze parti?
- Supporta processi deterministici di ID bridging e la riconciliazione retroattiva delle identità nel tempo?
- Come viene gestita l’identità a livello architettonico: all’interno di un sistema proprietario chiuso o in modo integrabile e interrogabile attraverso l’ecosistema di dati esistente?
- Gli output della risoluzione dell’identità sono accessibili e riutilizzabili tra i livelli di analisi, modellazione e attivazione, o sono confinati all’interno della piattaforma stessa?
In quest’ottica, una soluzione di identità cookieless non dovrebbe essere valutata esclusivamente sul tasso di corrispondenza (match rate), ma su quanto efficacemente l’identità possa essere utilizzata come asset condiviso per supportare insight, previsioni e attivazioni in modo coerente e sostenibile nel tempo.
L’approccio di Bytek alla Cookieless Identity Resolution
All’interno di questo framework, la Bytek Prediction Platform interpreta l’identity resolution come una funzione strutturale a supporto dell’analisi e della previsione, piuttosto che come un output isolato o un semplice livello di unificazione dei profili. L’identità viene risolta collegando identificatori, eventi e attributi provenienti da fonti eterogenee, con l’obiettivo di garantire continuità e coerenza lungo l’intero ciclo di vita dell’utente.
La Bytek Prediction Platform opera direttamente all’interno dell’ambiente del data warehouse, evitando la duplicazione dei dati e mantenendo le relazioni tra gli identificatori esplicite e interrogabili. In questo modo, la risoluzione dell’identità diventa la base operativa su cui vengono costruiti modelli predittivi come propensione, churn o Customer Lifetime Value, consentendo loro di lavorare su profili non frammentati e storicamente coerenti.
Questo approccio consente ai brand di sfruttare appieno i dati di prima parte mantenendo il controllo completo, supportare processi avanzati di ID bridging e alimentare attivazioni di marketing e media basate su insight predittivi, il tutto in linea con i principi di privacy-by-design.


