Die schrittweise Abschaffung von Drittanbieter-Cookies hat nicht nur eine Tracking-Technologie entfernt. Sie hat die Art und Weise, wie Marken die digitale Identität ihrer Nutzer aufbauen, pflegen und aktivieren, grundlegend infrage gestellt. In einem Kontext, der von zunehmend restriktiven Browsern, strengeren Datenschutzbestimmungen und steigenden Verbrauchererwartungen geprägt ist, kann die Identitätsauflösung nicht länger als Nebenfunktion des Martech-Stacks, sondern als ein langfristiges strategisches Gut betrachtet werden.
In diesem Cookieless-Szenario werden Plattformen zur Identitätsauflösung zu einem Schlüsselelement, um kanalübergreifende Kontinuität, Datenkonsistenz und Aktivierungsfähigkeiten zu gewährleisten, ohne sich auf undurchsichtige Identifikatoren oder externe Ökosysteme zu verlassen. Der Fokus verlagert sich auf First-Party-Ansätze, die darauf abzielen, proprietäre Daten zu verbessern, ID-Bridging-Prozesse zu ermöglichen und einen soliden digitalen Identitätsgraphen innerhalb des modernen Daten-Stacks zu strukturieren.
Dieser Leitfaden zielt nicht darauf ab, die Identitätsauflösung neu zu definieren, sondern einen praktischen und architektonischen Rahmen dafür zu bieten, wie sie in skalierbarer, datenschutzorientierter und konformer Weise konzipiert, bewertet und operationalisiert werden kann, um sie wirklich für die Aktivierung in Marketing, Medien und Analysen bereit zu machen.
Warum die Cookieless Identitätsauflösung einen neuen architektonischen Ansatz erfordert
Im Cookie-basierten Paradigma wurde die digitale Identität oft nachträglich abgeleitet, anstatt strukturiert konzipiert zu werden. Drittanbieter-Cookies fungierten lange Zeit als technische Abkürzung: ein probabilistischer Mechanismus, der undurchsichtig und zunehmend unzuverlässig war, insbesondere hinsichtlich Kontrolle, Datenqualität und Compliance.
Beim Übergang zu einem Cookieless-Szenario erfordert die Identitätsauflösung einen radikal anderen Ansatz. Sie kann sich nicht länger auf fragile Korrelationen verlassen, sondern muss nach klaren Prinzipien konzipiert werden:
- Deterministisch, wo möglich, um Konsistenz und Wiederholbarkeit über die Zeit zu gewährleisten.
- First-Party by Design, basierend auf proprietären und rechtmäßig gesammelten Identifikatoren.
- Persistent über den gesamten Nutzerlebenszyklus, über verschiedene Kanäle und Geräte hinweg.
- Unabhängig von Medienplattformen, um technologische und informationelle Abhängigkeiten zu vermeiden.
- Direkt von der Marke gesteuert, hinsichtlich Logik, Prioritäten und Nutzungsrichtlinien.
Dieser Paradigmenwechsel verschiebt die Identitätsauflösung von einer taktischen Adtech-Funktion zu einer grundlegenden Schicht, auf der Analyse, Prognose und Aktivierung aufbauen.
Aus dieser Perspektive ist eine moderne Cookieless-Identitätslösung nicht länger ein einfaches Plug-in oder eine Tracking-Schicht, sondern eine zentrale architektonische Komponente, die zwischen Datenerfassung, Analysen, KI-Modellierung und Omnichannel-Aktivierung positioniert ist.
First-Party Identitätsauflösung: Von Datenhoheit zu Kontrolle
Im Kern jeder wirklich nachhaltigen Cookieless-Strategie liegt die First-Party Identitätsauflösung. Ohne Drittanbieter-Cookies besteht die einzige Möglichkeit, Kontinuität und Kontrolle über die Identität zu gewährleisten, darin, sie aus Identifikatoren aufzubauen, die die Marke besitzt, verwaltet und rechtmäßig nutzen kann.
Im Gegensatz zu Drittanbieter-basierten Ansätzen stützt sich die First-Party Identitätsauflösung ausschließlich auf proprietäre Identifikatoren, darunter:
- Gehashte E-Mails (HEM)
- CRM-IDs oder Kunden-IDs
- Benutzer-IDs, die mit authentifizierten Sitzungen verknüpft sind
- Loyalitäts-, Mitgliedschafts- oder Abonnement-Identifikatoren
Die Identität wird daher durch eine Vielzahl von Identifikatoren repräsentiert, die koexistieren, da sie als Datenaustauschformate über verschiedene Plattformen hinweg verwendet werden. Alternative IDs, spezifische PIIs oder Kundenidentifikatoren werden oft übernommen, um Integrations-, Aktivierungs- oder Compliance-Anforderungen einzelner Systeme zu erfüllen. Das Ergebnis ist ein Ökosystem, in dem dieselbe Person durch mehrere legitime IDs repräsentiert wird, die verteilt und nicht aufeinander abgestimmt sind.
Das entscheidende Problem ist nicht die Art des Identifikators selbst, sondern seine kohärente und gesteuerte Übernahme als Verknüpfungsschlüssel über heterogene Datensätze hinweg. Ohne eine strukturierte Logik zur Verknüpfung dieser IDs bleiben selbst die besten Identifikatoren isoliert, schwer abfragbar und in konsistenter Weise schlecht aktivierbar.
ID-Bridging: Fragmentierte Identitäten über die Zeit verbinden
Selbst in einem vollständig First-Party-Kontext ist die digitale Identität niemals statisch oder sofort vollständig. Nutzer können anonym mit dem Browsen beginnen, sich später authentifizieren, Geräte wechseln oder zwischen digitalen und physischen Interaktionen alternieren. In dieser fragmentierten Dynamik wird ID-Bridging zu einem strukturellen Element der Identitätsauflösung.
ID-Bridging bezieht sich auf den kontrollierten und deterministischen Prozess, durch den mehrere Identifikatoren, die derselben Person zugeordnet werden können, über die Zeit hinweg miteinander verbunden werden. Praktisch bedeutet dies, eine anonyme Sitzungs-ID mit einer authentifizierten Benutzer-ID beim Login zu verknüpfen, eine CRM-ID mit einer gehashten E-Mail (HEM) abzugleichen, die in anderen Systemen verwendet wird, oder Online-Identifikatoren mit Transaktions-IDs aus dem Ladengeschäft zu verknüpfen, wodurch eine kontinuierliche Customer Journey über digitale und physische Touchpoints hinweg rekonstruiert wird.
Ein ausgereifter Ansatz für das ID-Bridging überschreibt Identitäten nicht einfach oder erzwingt einen statischen, einzelnen Schlüssel. Stattdessen bewahrt er die Beziehungen zwischen Identifikatoren, indem er deren Historie, zeitliche Abfolge und Ursprungskontext beibehält. Identität wird somit als eine Reihe sich entwickelnder Verbindungen behandelt und nicht als eine starre, ein für alle Mal definierte Entität.
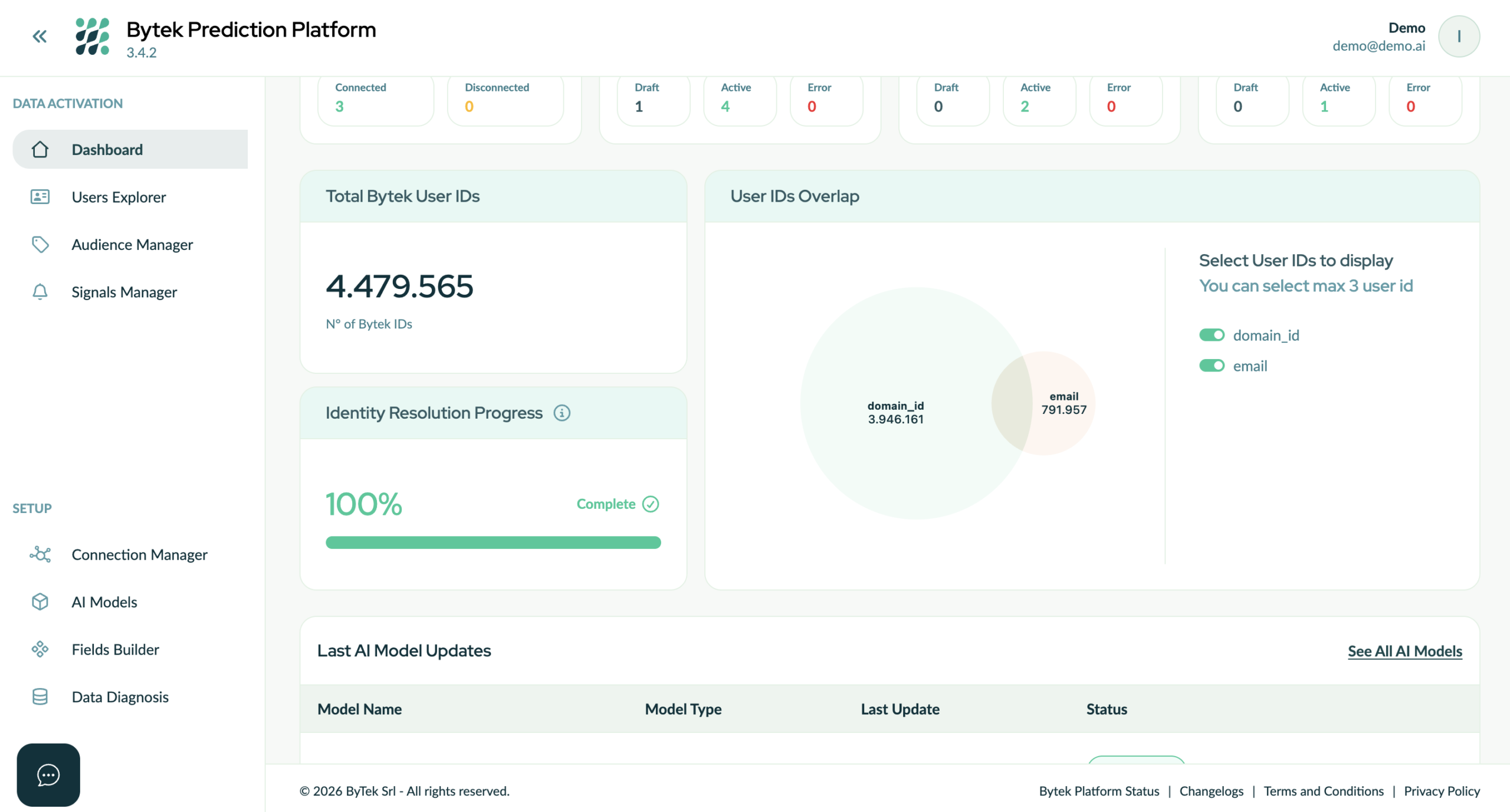
IMG – Die Bytek Prediction Platform kann die verschiedenen Identifikatoren, die im Data Warehouse verwendet werden und aus verschiedenen Unternehmenssystemen stammen, verknüpfen und eine eindeutige Bytek-ID generieren, die die verschiedenen Sub-IDs verbindet.
Dieses Modell ermöglicht retrospektives Identity Stitching, unterstützt eine genaue Attribution auch über lange Konversionszyklen hinweg und erlaubt die Erstellung kohärenter, aktivierbarer Zielgruppen, selbst wenn Signale partiell oder intermittierend sind. In diesem Sinne ist ID-Bridging das, was der Identitätsauflösung eine realistische Skalierung ermöglicht, indem es der Komplexität realer Customer Journeys gerecht wird, ohne Datenqualität, Governance oder analytische Zuverlässigkeit zu opfern.
Der digitale Identitätsgraph als strategisches Gut
Wenn die Identitätsauflösung korrekt implementiert wird, ist das Ergebnis nicht einfach ein vereinheitlichtes Profil, sondern der Aufbau eines digitalen Identitätsgraphen. Dieses Modell stellt die Identität als dynamisches Netzwerk dar, in dem Benutzer zentrale Knoten sind, die über Beziehungen, die sich im Laufe der Zeit entwickeln, mit Identifikatoren, Geräten und Touchpoints verbunden sind.
Im Gegensatz zu traditionellen Kundentabellen, die statisch und starr sind, ist ein Identitätsgraph dynamisch und erweiterbar. Er kann neue Signale, neue Identifikatoren und neue Interaktionen integrieren, ohne die historische Kohärenz zu verlieren. Aufgrund dieser Struktur eignet er sich besonders gut für fortgeschrittene Analysen und KI-gesteuerte Anwendungsfälle, bei denen Identitätsqualität und Kontinuität grundlegende Voraussetzungen sind.
Innerhalb dieses Rahmens können Marketing- und Datenteams:
- Zielgruppen über verschiedene Kanäle und Zeitfenster hinweg abfragen.
- Profile schrittweise mit Verhaltens- und Transaktionsmerkmalen anreichern.
- Prädiktive Modelle mit kohärenten und persistenten Identitätssignalen speisen.
- Erkenntnisse und Segmentierungen ohne Duplizierung, Fragmentierung oder Systemkonflikte aktivieren.
In diesem Sinne wird der digitale Identitätsgraph zum wahren Rückgrat der Entscheidungsintelligenz: kein einfacher Abgleichmechanismus, sondern die Infrastruktur, die ein konsistentes Verständnis, eine Vorhersage und eine Aktivierung des Kundenverhaltens ermöglicht.
Die Rolle des Bytek Tags von Adenty bei der Cookieless Identitätsauflösung
Der Bytek Tag von Adenty ermöglicht die Erfassung von Navigations- und digitalen Interaktionssignalen über mehrere Domains und Sitzungen hinweg und generiert einen persistenten probabilistischen Identifikator. Dieser Identifikator ermöglicht es, denselben Benutzer über die Zeit hinweg wiederzuerkennen, wodurch die für Cookieless-Umgebungen typische Fragmentierung reduziert und die Kontinuität auch dann aufrechterhalten wird, wenn deterministische Identifikatoren nicht sofort verfügbar sind.
Wenn Benutzer freiwillig identifizierende Daten, wie z. B. eine E-Mail-Adresse, angeben, verwaltet der Bytek Tag deren Erfassung in gehashter Form, im Einklang mit den Privacy-by-Design-Prinzipien.
Persönlich identifizierbare Informationen (PII), die ausschließlich auf freiwilliger Basis gesammelt und in gehashter Form verarbeitet werden, dienen der Stabilisierung und Konsolidierung der Identität über die Zeit. Dies ermöglicht eine zuverlässigere Zuordnung von Interaktionen und Signalen, die andernfalls ohne Login fragmentiert blieben.
In diesem Kontext trägt der Bytek Tag dazu bei, die Identitätskontinuität über Sitzungen und Domains hinweg zu gewährleisten und die Ereignisabstimmung sowie die Entwicklung von Profilen von probabilistischen zu stabileren Identifikationen zu unterstützen. Diese Konsistenz macht Daten über den gesamten Lebenszyklus innerhalb des modernen Daten-Stacks kohärent nutzbar.
Plattformen zur Identitätsauflösung und der moderne Daten-Stack
Historisch wurde die Identitätsauflösung als Nebenfunktion innerhalb von Werbe-, CRM- oder Marketing-Automatisierungstools behandelt. In diesen älteren Modellen war die Verknüpfung von Identifikatoren oft auf einzelne Kanäle beschränkt, basierte auf unvollständigen Datensätzen und war stark von Drittanbieter-Cookies oder externen Identifikatoren abhängig. Das Ergebnis war eine fragmentierte Sicht auf den Benutzer, die über die Zeit hinweg schwer konsistent zu halten und schlecht für strukturierte Personalisierung, Messung und Governance geeignet war.
Plattformen zur Identitätsauflösung entstanden, um diese Einschränkungen zu überwinden, indem sie eine dedizierte Lösung für die Verwaltung der Identität über die gesamte Customer Journey hinweg einführten. Ihre Aufgabe ist es, Signale aus Online- und Offline-Quellen zu verbinden, sowohl bekannte als auch anonyme Benutzer zu erkennen und die Identität konsistent in Targeting-, Mess- und Personalisierungsprozessen nutzbar zu machen.
Enterprise-Plattformen zur Identitätsauflösung teilen heute einen Kernsatz von Funktionen. Sie unterstützen das Onboarding und den Abgleich von Daten aus heterogenen Quellen, bauen einen Identitätsgraphen auf, der Beziehungen zwischen Personen, Geräten und Touchpoints darstellt, ermöglichen es Marken, die volle Kontrolle über First-Party-Daten zu behalten, und nutzen persistente Identifikatoren auf individueller oder Haushaltsebene. In diesem Kontext wird Identität nicht als statischer Zustand, sondern als sich entwickelnde Struktur behandelt, bei der historische Daten retrospektiv abgeglichen werden können, wenn neue Identifikatoren oder Authentifizierungssignale auftauchen. Diese Funktionen werden durch Compliance-Merkmale, Einwilligungsmanagement und die Integration mit Drittsystemen über APIs ergänzt.
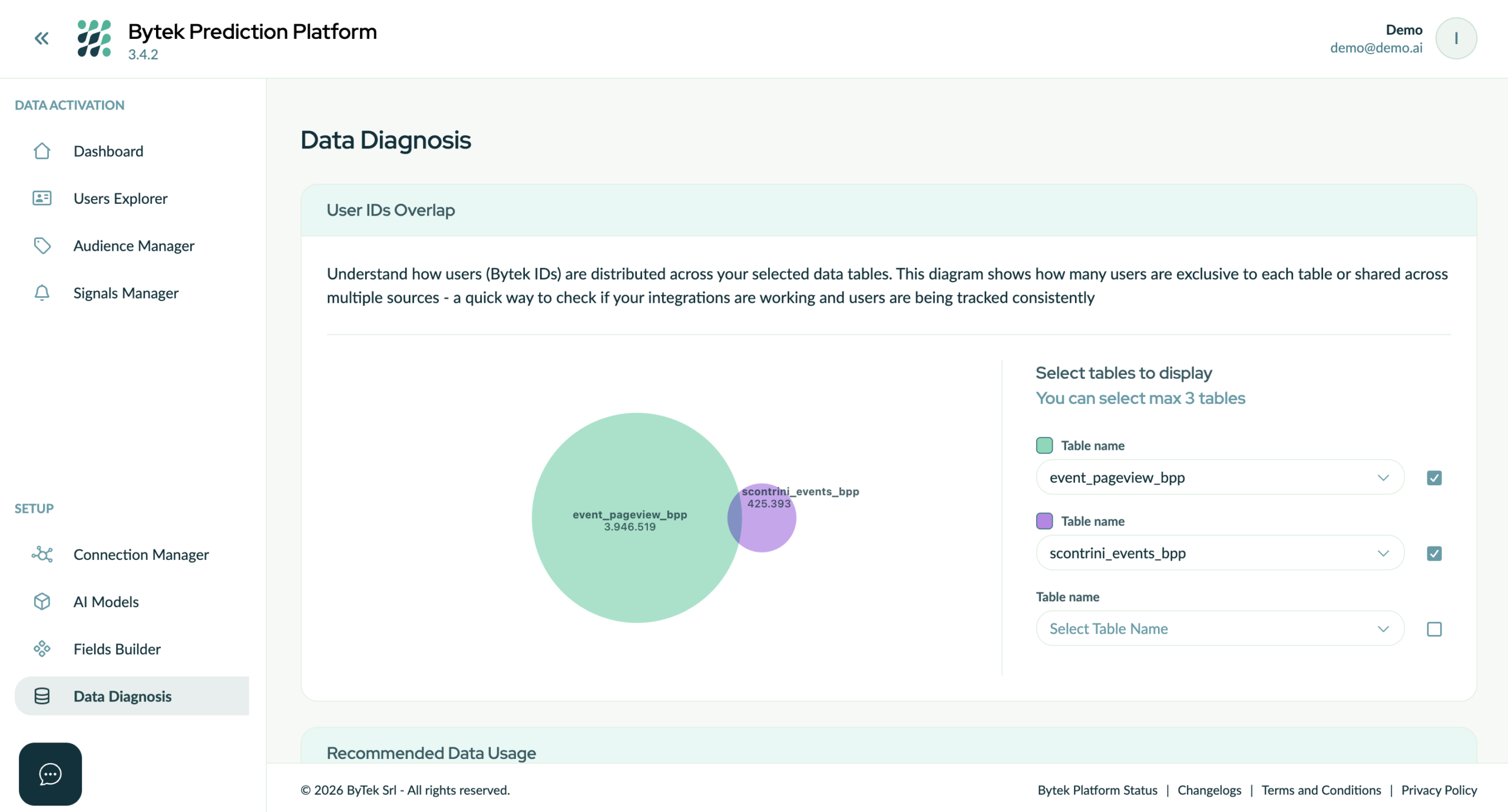
IMG – Nach der Einführung der Identitätsauflösung wendet die Bytek Prediction Platform diese direkt auf die Data-Warehouse-Tabellen an, wodurch die Identifizierung von Überschneidungen zwischen Tabellen hinsichtlich erkannter Benutzer ermöglicht wird.
Jenseits dieses gemeinsamen Kerns bieten viele Plattformen erweiterte Funktionalitäten, die ihren Anwendungsbereich erweitern, darunter Match-Confidence-Scoring, Integration mit Data Clean Rooms, private oder kooperative Identitätsgraphen und vorgefertigte Verbindungen mit dem Martech- und Adtech-Ökosystem. Auf diese Weise entwickelt sich die Identitätsauflösung von einem einfachen Deduplizierungsprozess zu einer zentralen Komponente der Marketinginfrastruktur.
Aus Nutzensicht ermöglicht die Einführung einer Identitätsauflösungsplattform tiefere Kundeneinblicke, verbessert die Genauigkeit der Personalisierung und liefert konsistentere Erlebnisse über alle Kanäle hinweg. Gleichzeitig unterstützt die Verwendung persistenter Identifikatoren eine zuverlässigere kanalübergreifende Messung, stärkere Attributionsmodelle und ein rigoroseres Management von Datenschutz, Präferenzen und Compliance.
Datenschutz, Compliance und Trust by Design
Die Fähigkeit, Benutzer heute zu erkennen, muss mit einer strengeren Regulierung und einer wachsenden Aufmerksamkeit der Verbraucher für die Verwendung persönlicher Daten einhergehen.
In diesem Kontext muss eine wirklich robuste Identitätsauflösungsplattform von Anfang an so konzipiert sein, dass sie die Verarbeitung personenbezogener Daten im Klartext vermeidet, sich auf verschlüsselte und anonymisierte Identifikatoren stützt, Einwilligungssignale systemübergreifend konsistent respektiert und Auditierbarkeit und Daten-Governance über den gesamten Datenlebenszyklus hinweg gewährleistet.
Wenn die Identität innerhalb von First-Party-Grenzen aufgelöst und direkt auf der Datenebene verwaltet wird, ist die Einhaltung von Vorschriften wie der DSGVO und dem CCPA keine nachträgliche Einschränkung mehr, sondern ein strukturelles Merkmal der Architektur. Genau dieser Ansatz ermöglicht es, Personalisierung und Aktivierung zu skalieren, ohne das Vertrauen der Nutzer zu gefährden, wodurch Datenschutz und Leistung zu komplementären und nicht zu gegensätzlichen Dimensionen werden.
Wie man eine Cookieless-Identitätslösung bewertet
Bei der Bewertung einer Identitätsauflösungsplattform in einem Cookieless-Szenario sollten Marketing- und Datenverantwortliche eine Reihe von Schlüsselfragen stellen, um wirklich strukturelle Lösungen von partiellen oder rein taktischen Ansätzen zu unterscheiden:
- Ist die Lösung First-Party by Design, oder stützt sie sich immer noch auf externe Identifikatoren und Drittanbieter-Ökosysteme?
- Unterstützt sie deterministische ID-Bridging-Prozesse und die retrospektive Abstimmung von Identitäten über die Zeit hinweg?
- Wie wird die Identität architektonisch verwaltet: innerhalb eines proprietären, geschlossenen Systems oder auf eine integrierbare und abfragbare Weise über das bestehende Datenökosystem hinweg?
- Sind die Ergebnisse der Identitätsauflösung zugänglich und wiederverwendbar über Analyse-, Modellierungs- und Aktivierungsschichten hinweg, oder sind sie auf die Plattform selbst beschränkt?
Aus dieser Perspektive sollte eine Cookieless-Identitätslösung nicht nur anhand der Match-Rate bewertet werden, sondern danach, wie effektiv die Identität als gemeinsames Gut genutzt werden kann, um Einblicke, Vorhersagen und Aktivierungen kohärent und nachhaltig über die Zeit hinweg zu unterstützen.
Der Bytek-Ansatz zur Cookieless Identitätsauflösung
Innerhalb dieses Rahmens interpretiert die Bytek Prediction Platform die Identitätsauflösung als strukturelle Funktion zur Unterstützung von Analyse und Prognose, anstatt als isoliertes Ergebnis oder einfache Profilvereinheitlichungsschicht. Die Identität wird durch die Verknüpfung von Identifikatoren, Ereignissen und Attributen aus heterogenen Quellen aufgelöst, mit dem Ziel, Kontinuität und Kohärenz über den gesamten Nutzerlebenszyklus hinweg zu gewährleisten.
Die Bytek Prediction Platform arbeitet direkt in der Data-Warehouse-Umgebung, vermeidet Datenredundanz und hält Beziehungen zwischen Identifikatoren explizit und abfragbar. Auf diese Weise wird die Identitätsauflösung zur operativen Grundlage, auf der prädiktive Modelle wie Propensity, Churn oder Customer Lifetime Value aufgebaut werden, wodurch sie auf nicht fragmentierten, historisch konsistenten Profilen arbeiten können.
Dieser Ansatz ermöglicht es Marken, First-Party-Daten vollständig zu nutzen und dabei die volle Kontrolle zu behalten, fortschrittliche ID-Bridging-Prozesse zu unterstützen und Marketing- und Medienaktivierungen auf der Grundlage prädiktiver Erkenntnisse zu steuern, alles im Einklang mit den Privacy-by-Design-Prinzipien.


